What I wish I knew when learning OCaml
This is a poorly structured list of common questions and answers about OCaml I had to ask myself or have been asked often.
→ The language
→ The double semicolon
The answer to the question “When do I need the ;; within OCaml source code?” is never.
It's not a part of the language and is only used by the interpreter as an end of input mark.
If you want to execute something for its side effects and don't care about its return value, you should wrap it in a let-expression and match it against the wildcard pattern:
let _ = print_endline "hello world" let _ = exit 0
If you call a function that returns unit, you can also match the result against the unit value, () .
let () = print_endline "hello world"
The advantage over wildcard is that if you accidentally write an expression that has type other than unit (e.g. forget the argument), the compiler will throw a type error.
Note: If you use ocaml as a non-interactive script interpreter (i.e. ocaml /path/to/file.ml ), you do need the ;; after directives, as in #use "topfind";; . But the directives are not part of the language either.
Historical note: In CAML Light, the predecessor of OCaml, double semicolons were mandatory. For this reason they are quite common in old code originally written in CAML Light or written in the early days of OCaml. These days they are considered a bad style.
→ Semicolons and expression sequences
Semicolon is an expression separator, not a statement terminator.
This code
let foo x y =
print_endline "Now I'll add up two numbers";
print_endline "Yes, seriously";
x + y
is semantically equivalent to
let foo x y =
let _ = print_endline "Now I'll add up two numbers" in
let _ = print_endline "Yes, seriously" in
x + y
Therefore, if you end a sequence of expressions with a semicolon, whatever comes next will be treated as the last expression of the sequence, and will likely cause a syntax error (e.g. if the next thing is a let binding) or, worse, incorrect behaviour.
→ Shadowing is not mutation
Some uses of top level let bindings may look like mutation, but they actually aren't.
let x = 10 let x = x + 10 let () = Printf.printf "%d\n" x
In this example, the x in the printf expression is 20. Did we redefine x for the whole program?
The answer is no. Every let binding opens a new scope. In case of top level bindings, the scope they open continues until the end of the file. So “let x = x + 10” takes the value of x from the outer scope, adds 10 to it, and opens a new scope where x is bound to 20.
However, it has no effect on the outer scope. We can demonstrate it by creating some closures that use the old x.
let x = 10 let print_old_x () = Printf.printf "%d\n" x let x = x + 10 let () = Printf.printf "%d\n" x (* prints 20 *) let () = print_old_x () (* prints 10 *)
→ Functions and currying
The good thing about currying in OCaml and other ML-style languages is that you don't need to know what currying is to use it. Every time you create a function of “multiple arguments”, you really create a curried function. Which means that
let add x y = x + y
is a sugar for
let add =
fun x ->
fun y -> x + y
This makes partial application very easy: just omit some of the arguments and what you get is a new function.
# let add1 = add 1 ;; val add1 : int -> int = <fun>
To be precise, what you get is a closure: a function plus an environment where name x is bound to 1, but you don't need to think about it to use it.
Note: this is also the reason OCaml never gives you “too few arguments” errors if you forget an argument. Only when you try to use that value, it tells you that your value has type foo → bar but was expected to have type bar. If you see an error like that, check for missing arguments. Example:
# (add 1) + 9 ;; Error: This expression has type int -> int but an expression was expected of type int
→ Mutable record fields vs. references
They are the same thing. A reference is a record with the sole mutable field called “contents”, as you can see from the Pervasives source code.
type 'a ref = { mutable contents : 'a }
let (:=) r v = r.contents <- v
let (!) r = r.contents
Therefore the choice between references and mutable fields is mostly aesthetic. However, if you store references in record fields, converting them to mutable records may make the code slightly faster.
→ Is there any difference between begin/end and parentheses?
Not really. The real difference between begin/end in OCaml and identical looking construct in Pascal (or curly braces in C) is that in Pascal, they create a compound statement, while in OCaml they work as expression delimiters. In other words, it's just a more readable alternative to parentheses.
Consider these examples:
let foo () =
(for i = 1 to 3 do
print_endline "I'll return 0, I tell you!"
done);
0
let x = 3 + begin 2 end
→ Type definitions
The ML term for a tuple is product type. A natural example of a product type is a point on a plane that has X and Y coordinates.
type point = float * float
Product types are rarely named, and the compiler will not start calling everything that is float * float a point after you declare this type. They are usually implicit or incorporated into definitions of sum types and records.
Another kind of types that has no direct analogy in most other languages is sum type (variant records in Pascal and Ada are pretty close). Easier to show than to explain. An example: in color printing, dot color is either the key color (usually black) or a combination of cyan, yellow, and magenta. We can represent colors with this type:
type color = Key | Color of int * int * int
Sum and product types are referred to as algebraic data types.
Some jargon you should know:
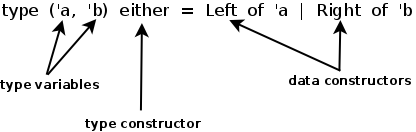
A type is polymorphic if there are free type variables — placeholders that can be substituted for any type. Type names are often referred to as type constructors (a polymorphic type 'a list can produce int list , string list and so on).
Type variables are always prefixed with an apostrophe, names can be arbitrary. This is perfectly acceptable:
type ('result, 'error) result = Success of 'result | Error of 'error
The elements of a sum type, such as Left and Right above, are called data constructors. Their names must be capitalized. Data constructors can be nullary, this is equivalent to enumerated types in other languages such as C enum.
type ml = OCaml | SML | FSharp (* Nullary constructors *)
There are two types for which special syntactic sugar is provided: unit and list. In imaginary syntax their definitions can be written as:
type unit = () type 'a list = 'a :: 'a list | []
The () and :: are special only syntactically, otherwise they are just data constructors like any other and can be used in pattern matching and anywhere else where normal constructors are allowed.
Note: in print and blackboard writing people often use greek letters for type variables, e.g. α list rather than 'a list . Likewise, the * in product types is often substituted for the × sign.
→ let vs. let rec
At first the rec keyword may look like syntactic noise, but it isn't.
If the name of your binding is unique within the scope, rec simply allows you to refer to its name within your expression, but if you are shadowing another binding, it allows you to choose whether that name will refer to the older binding or to the newly defined one.
An example: suppose you want to redefine the incr function from Pervasives so that it prints a debug message when called.
Let's define it. Note the lack of rec.
let incr i =
print_endline "Counter was incremented";
incr i
Now let's try it.
# let x = ref 0 ;;
val x : int ref = {contents = 0}
# incr x ;;
Counter was incremented
- : unit = ()
# !x ;;
- : int = 1
This works as expected, our new incr calls the old incr, and everything within our new scope refers to the new incr definition.
However, if we use a definition with rec, incr i within our definition will refer to the new definition of incr rather than incr from Pervasives, thus creating a useless infinite loop.
→ let vs. let ... and (mutually recursive bindings)
At first the and keyword may look like syntactic sugar that allows one to avoid writing let second time. While it can be used this way (though arguably shouldn't), there's a deeper distinction between a sequence of let ... in bindings and let ... and ...
The distinction is that the and keyword allows mutually recursive bindings.
Consider this inefficient but illustrative example of functions that check if given number is even or odd:
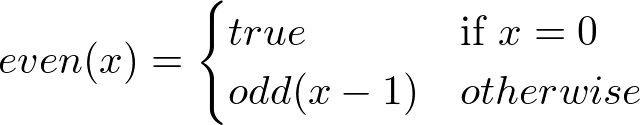
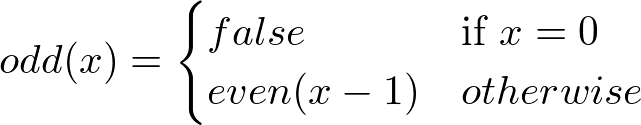
None of them refers to itself, but they refer to each other, which makes them mutually recursive. The naive attempt to translate that definition to OCaml:
let even x =
match x with
| 0 -> true
| _ -> odd (x - 1)
let odd x =
mach x with
| 0 -> false
| _ -> even (x - 1)
will fail with Error: Unbound value odd error. That's because in the scope where even is defined, odd is not defined yet (remember that every let binding opens a new scope).
This is where the and keyword comes into play: by using it, we can make OCaml treat multiple bindings in a single new scope. This version will work as expected:
let rec even x =
match x with
| 0 -> true
| _ -> odd (x - 1)
and odd x =
match x with
| 0 -> false
| _ -> even (x - 1)
;;
# odd 19 ;;
- : bool = true
# even 42 ;;
- : bool = true
→ Abstract types
Abstract types is a way to implement encapsulation. A type is treated as abstract if module interface doesn't expose anything but its name.
In object oriented programming, hiding values inside objects serve two purposes: to abstract from implementation details, and to prevent invariant violations. These tasks are not really related to each other though, and it can be done with different mechanisms.
In ML modules, we may hide (rather, not expose) functions to avoid cluttering the interface with implementation details. But if those functions are used with values that come from the outside world, how do we protect invariants? ML gives us ability to hide a type implementation inside a module and make functions work with that type rather than types known to the outside world. Then we can provide a function that creates values of that type.
Suppose we want to write a module for working with natural numbers whose values cannot be negative. Internally, the type we are working with will be int, but no one outside the module will know this, and therefore will not be able to use it with our functions without converting it first.
module type NATURAL = sig
exception Negative_argument
type t (* No implementation *)
val from_int : int -> t (* Convert an int to the mysterious type t *)
val to_int : t -> int (* Convert back to int *)
val add : t -> t -> t (* Note: t -> t, not int -> int *)
end
module Natural : NATURAL = struct
type t = int
exception Negative_argument
let from_int x =
if x < 0 then raise Negative_argument else x
let to_int x = x
let add x y = x + y
end
Let's see how it works:
# Natural.add 3 2 ;; Error: This expression has type int but an expression was expected of type Natural.t # Positive.from_int (-10) ;; Exception: Natural.Negative_argument. # let a = Natural.add (Natural.from_int 4) (Natural.from_int 3) ;; val a : t = <abstr> # Natural.to_int a ;; - : int = 7
The type t is indeed int internally, but leaving it abstract makes OCaml treat it as a distinct type. If we change the signature to use type t = int, the add function will work with any values of the type int. If we make the add function int → int rather than t → t, it will have the same effect:
# Natural.add (-9) 8 ;; - : int = -1
→ The toolchain
→ Compiled? Interpreted?
OCaml is a good demonstration that the terms “compiled language” and “interpreted language” are meaningless. Right in the distribution, there are:
- An interpreter
- A bytecode compiler and bytecode interpreter
- A native code compiler
The interpreter can work in both interactive mode (read-eval-print loop) and batch mode, like shell or Perl or Python.
The bytecode compiler is useful on platforms where the native compiler is not available (e.g. MIPS), or for bootstrapping the native code compiler on new machines (the bytecode interpreter is written in C). You can also produce Javascript from OCaml bytecode files with js_of_ocaml.
Bytecode executables are a lot slower than native ones, so most of the time people either use the interpreter for exploratory programming and scripting or compile to native code.
Due to this, there are multiple executables:
- ocaml
- The interpreter
- ocamlc
- The bytecode executable of the bytecode compiler
- ocamlc.opt
- The native executable of the bytecode compiler
- ocamlopt
- The bytecode executable of the native code compiler
- ocamlopt.opt
- The native executable of the native code compiler
Fortunately, you don't have to remember it in most cases.
Note: the REPL is often referred to as “toplevel”.
→ Interactive interpreter is annoying to use
No history, no completion, almost no line editing. A perfect environment for exploratory programming indeed.
There are two things you can do: use ocaml with rlwrap, or install utop.
If you want function name completion, utop is a better choice.
→ How do I load source code files into the REPL?
In the REPL you can load source files and binary libraries with interpreter directives. Directives start with # character, which sometimes confuses readers because # is also the REPL prompt.
If you want to load all definitions from file.ml into the REPL:
#use "program.ml";;
If you want to load a file as a module:
#mod_use "program.ml";;
For demonstration, suppose you have a file named program.ml in your current directory with contents:
let hello () = print_endline "hello world"
Here's a session transcript that demonstrates how these directives work:
$ ocaml
OCaml version 4.02.1
# #use "program.ml";;
val hello : unit -> unit = <fun>
# #mod_use "program.ml";;
module Program : sig val hello : unit -> unit end
# hello () ;;
hello world
- : unit = ()
# Program.hello () ;;
hello world
- : unit = ()
→ How do I load compiled libraries in the REPL?
If you have findlib installed and the library you want to load was installed with e.g. OPAM, the easiest way is to load the findlib package. For this purpose, findlib installs a handler for #require directive that can automatically load a package and its dependencies.
In utop, the topfind library is loaded by default, in standard OCaml REPL you'll have to load it yourself with #use "topfind";;
Then you can list available packages with #list;; and load packages you want, e.g. #require "unix";; .
If you want to load a library that is not installed, use #load directive, as in #load "somedir/mylib.cma";; . Note that unlike findlib's #require , #load does not automatically load dependencies.
→ How do I link libraries
The easiest way to compile a program that uses libraries is to use ocamlfind from findlib.
ocamlfind ocamlopt -package unix -o prog.native prog.ml ocamlfind ocamlc -package unix -o prog.byte prog.ml
You can do it by hand, but you'll have to specify different library file names (.cma vs .cmxa) for bytecode and native versions, while ocamlfind will do it automatically for you.
→ How do I produce module signatures automatically?
Global type inference makes it possible.
ocamlc -i mymodule.ml > mymodule.mli
Sadly, it can't automatically update existing signatures (add what's missing and preserve what's already there if it was edited by hand), but copying autogenerated lines is still faster than writing them by hand.